Page object model (POM) in selenium is an object design pattern that is used to create an object repository for web UI elements.
It is one of the most widely used design patterns by the community of Selenium WebDriver across the world.
In this model, we create a separate corresponding page class for each web page in the application and store all locators to inspect elements on the page, respective methods to interact with those elements, and variables to use them.

Each page class will locate the WebElements of the corresponding web page and perform operations on those WebElements by methods.
The test classes use methods of this page object class whenever they need to perform a test with the UI of that page.
The main benefit here is that, if the UI of webpage some changes in the future then the tests need not to be changed, only the code within the page class needs to be changed.
After that, all the changes that support the new UI of web page are located in one place. Therefore, locators and test scripts are stored separately in the Selenium page object model.
Why Page Object Model (POM)?
The need or use of page object model in Selenium is due to the following reasons:
1. Duplication of code: On increasing selenium test cases, if locators are not properly organized, it results difficulty to maintain project structure because of too many duplications of code used in the project.
Duplicate code is mainly caused by duplicate functionality that results in duplicate usage of locators.
Hence, the project is less maintainable. By using the page object model design pattern in the project, we can reduce or eliminate duplicate test code.
2. Less Time Consumption: If we have a small script, it is easy to maintain the test script in less time. But if the test suite contains 10 different test scripts using the same page element then on any change happens in that page element, we will need to modify all 10 scripts which becomes a very tough and time-consuming task.
So, a better and systematic approach for script maintenance is to create a separate page class that would find web elements. This class can be reused in all the scripts using that element.
3. Code Maintenance: In the future, if there is a change in the web element, we will need to make the change in just 1 page class and not in the 10 different scripts. This approach can be achieved using POM which makes code reusable, readable, and maintainable.
How to Implement POM in Selenium?
There are two ways by which we can implement page object model design patterns in Selenium. They are as follows:
1. Using Normal approach.
2. Using Page Factory and @findBy
Let’s understand the concepts of normal approach and page factory one by one.
Creating Page Object Model using Normal Approach in Selenium
Normal approach is a basic structure of Page object model (POM) without using Page factory where all Web Elements of the application under test and the method that performs operations on these Web Elements, are maintained inside a class file.
Let’s take a scenario where we will automate the webpage by using normal approach (without using Page factory).
Scenario to Automate:
1. Go to the Facebook login page.
2. Get the title of Facebook login page.
3. Enter the valid credentials in the “Facebook Login” Page in order to redirect to the ‘Facebook Home‘ Page.
4. On the Facebook Home page, verify that “Facebook” is present or not.
5. And then log out from the account.
Now, you will observe in the above scenario that we are dealing with two web pages. First is Login Page and the second is Home Page that will come after login. Accordingly, we will create 2 POM classes.
Follow the below steps to implement the Page Object Model Design Pattern:
Step 1:
a. Create a package named com.facebook.pages.
b. Create classes for Facebook Login web page and Facebook Home page to hold element locators and their methods. To execute both page classes, we can create page objects for all available pages in the AUT.
c. Declare a WebDriver reference variable in each page class.
d. For each page class, create a constructor and pass WebDriver as an input parameter.
e. Locate all web elements using locators by using By.xpath and store them in variables of type By in one class as done in the following source code.
We can reuse these locators in multiple methods so that maintenance will be easy. If any change happens in the UI in the future, we can simply update one Page.
f. Create a method to perform operations on each web element in the class. Now, call findElement() method using driver reference and pass reference variables of type By.
Let’s write the following source code related to each page class.
Program source code 1:
package com.facebook.pages;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
public class FBLoginPage
{
// Create WebDriver reference variable.
WebDriver driver;
// Create a constructor and pass WebDriver reference.
public FBLoginPage(WebDriver driver)
{
this.driver = driver;
}
// Identify web elements using locators by By.xpath.
By titleText = By.xpath("//a[@title = 'Go to Facebook home']");
By username = By.xpath("//input[@id = 'email']");
By password = By.xpath("//input[@id = 'pass']");
By login = By.xpath("//input[@id = 'u_0_b']");
// Create a method to perform operations on each web element.
public void titleText()
{
String getText = driver.findElement(titleText).getText();
System.out.println("Title of Facebook Login Page: " +getText);
if(getText.equalsIgnoreCase("Facebook"))
{
System.out.println("Title is successfully verified");
}
else {
System.out.println("Something went wrong");
}
}
public void setUsername(String strUsername)
{
driver.findElement(username).sendKeys(strUsername);
}
public void setPassword(String strPassword)
{
driver.findElement(password).sendKeys(strPassword);
}
public void loginClick()
{
driver.findElement(login).click();
}
public void loginData(String strUsername, String strPassword)
{
this.titleText();
this.setUsername(strUsername);
this.setPassword(strPassword);
this.loginClick();
}
}Program source code 2: Follow all the steps as you are done in the previous coding.
package com.facebook.pages;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
public class FBHomePage
{
WebDriver driver;
public FBHomePage(WebDriver driver)
{
this.driver = driver;
}
By homepageTitle = By.xpath("//span[text() = 'Facebook']");
By userNavigationlevel = By.xpath("//div");
By logout = By.xpath("//text()[.='Log Out']/ancestor::span[1]");
public void homePageTitle()
{
String getHomepageTitle = driver.findElement(homepageTitle).getText();
System.out.println("Home Page Title : " +getHomepageTitle);
}
public void navigationLabel()
{
driver.findElement(userNavigationlevel).click();
}
public void logout()
{
driver.findElement(logout).click();
System.out.println("Logout successfully");
}
}Steps 2:
a. Create another package named com.facebook.tests.
b. Create a TestBase class. Here, we will create WebDriver object to launching the Firefox browser, maximize browser, implementing waits, launching URL and etc.
Look at the following source code for TestBase class.
Program source code 3:
package com.facebook.tests;
import org.testng.annotations.Test;
import com.facebook.pages.FBHomePage;
import com.facebook.pages.FBLoginPage;
import java.io.IOException;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeTest;
public class TestBase
{
// Declare WebDriver reference variable and make it static.
public static WebDriver driver = null;
// Declare @BeforeTest annotation that will execute method before running each unit test.
@BeforeTest
public void basicSetUp() throws IOException
{
driver = new FirefoxDriver();
// To maximize browser.
driver.manage().window().maximize();
// Implicit wait.
driver.manage().timeouts().implicitlyWait(20, TimeUnit.SECONDS);
// Open Facebook page.
driver.get("https://www.facebook.com");
}
// Declare @Test annotation and set priority equal to 0.
@Test(priority = 0)
public void login()
{
// Create an object of FBLoginPage class and pass WebDriver reference to its constructor.
FBLoginPage fblogin = new FBLoginPage(driver);
// Call loginData() method using reference variable fblogin and pass username and password as an input parameter.
fblogin.loginData("[email protected]", "xyz123");
}
// Declare another @Test annotation and set priority equal to 1.
@Test(priority = 1)
public void home()
{
// Create an object of FBHomePage and pass WebDriver reference to its constructor.
FBHomePage fbhome = new FBHomePage(driver);
fbhome.homePageTitle();
// Calling homePageTitle() method using reference variable fbhome.
fbhome.navigationLabel();
// Calling navigationLabel() method.
fbhome.logout(); // Calling logout() method.
}
// Declare @AfterTest annotation that will execute method after running each unit test.
@AfterTest
public void closingTest()
{
TestBase.driver.quit();
}
}In steps 3, we need to create the testng.xml file and link it to the preceding created test case class files. If you don’t know how to create TestNG XML file, you can follow the below link to learn step by step.
Step 4:
Creating a testng.xml file.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name = "Suite">
<test name = "Page Object Model Project">
<classes>
<class name = "com.facebook.tests.TestBase" />
</classes>
</test> <!-- Page Object Model Project -->
</suite> <!-- Suite -->On running this testng.xml file in the Eclipse, it will redirect to facebook.com web page in the Firefox browser and enter all the credentials.
It will then verify username and password and then log out of the account. This is how Page Object Model can be implemented in the Selenium project using normal approach without Page factory.
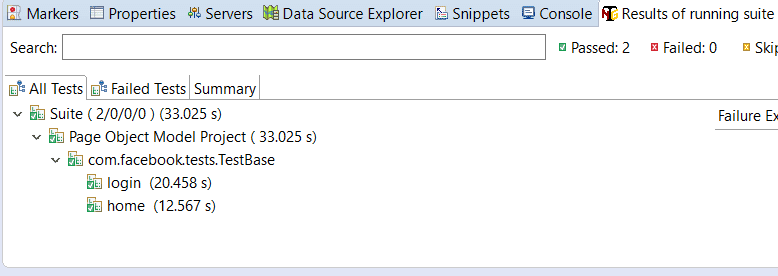
Now, look at a glance at the output of the above scenario.
Output:
Title of Facebook Login Page: Facebook
Title is successfully verified
Home Page Title : Facebook
Logout successfully
===============================================
Suite Total tests run: 2, Failures: 0, Skips: 0
===============================================Results of running test suits:
Let’s take another scenario that will clear all concepts better.
Scenario to Automate:
1. Open Home page https://www.pixabay.com.
2. Click on Login button on home page.
3. Enter the valid credentials on the Login page in order to redirect to the Portfolio page.
4. Click on profile image on Portfolio page.
5. Then log out from the account.
Now, you will observe in the above scenario that we are dealing with three web pages. First is Home Page, second is Login Page, and third is Portfolio Page that will come after login. Accordingly, we will create 3 page classes and one TestBase class.
Follow all the above important steps to implement Selenium Page Object Model in this scenario. Let’s understand the following source code.
1. Creating a Homepage class.
Program source code 4:
package com.pixabay.pages;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
public class Homepage
{
WebDriver driver;
public Homepage(WebDriver driver)
{
this.driver = driver;
}
By loginButton = By.xpath("//a[text() = 'Log in']");
public void clickloginButton()
{
driver.findElement(loginButton).click();
}
}2. Creating Login page class.
Program source code 5:
package com.pixabay.pages;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
public class Loginpage
{
WebDriver driver;
public Loginpage(WebDriver driver)
{
this.driver = driver;
}
By username = By.xpath("//input[@name = 'username']");
By password = By.xpath("//input[@name = 'password']");
By signIn = By.xpath("//input[@value = 'Log in']");
public void userName(String strUsername)
{
driver.findElement(username).sendKeys(strUsername);
}
public void passWord(String strPassword)
{
driver.findElement(password).sendKeys(strPassword);
}
public void signInButton()
{
driver.findElement(signIn).click();
}
}3. Now, create Portfolio page class.
Program source code 6:
package com.pixabay.pages;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
public class PortfolioPage
{
WebDriver driver;
public PortfolioPage(WebDriver driver)
{
this.driver = driver;
}
By proImage = By.xpath("//img[@class = 'profile_image']");
By logout = By.xpath("//a[text() = 'Log out']");
public void profileImage()
{
driver.findElement(proImage).click();
}
public void logoutButton()
{
driver.findElement(logout).click();
}
}4. Now, it’s time to create a TestBase class.
Program source code 7:
package com.pixabay.tests;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.Test;
import com.pixabay.pages.Homepage;
import com.pixabay.pages.Loginpage;
import com.pixabay.pages.PortfolioPage;
public class TestBase
{
public static WebDriver driver;
@BeforeTest
public void setUp()
{
driver = new FirefoxDriver();
driver.manage().window().maximize();
driver.get("https://www.pixabay.com");
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
}
@Test(priority = 0)
public void home()
{
Homepage hp = new Homepage(driver);
hp.clickloginButton();
}
@Test(priority = 1)
public void login()
{
Loginpage lp = new Loginpage(driver);
lp.userName("[email protected]");
lp.passWord("xyz123");
lp.signInButton();
}
@Test(priority = 2)
public void portFolio()
{
PortfolioPage pf = new PortfolioPage(driver);
pf.profileImage();
pf.logoutButton();
}
}5. In the last step, we need to create testng.xml file to run the above test script.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name = "Suite">
<test name = "Page Object Model Project">
<classes>
<class name = "com.pixabay.tests.TestBase" />
</classes>
</test> <!-- Page Object Model Project -->
</suite> <!-- Suite -->On running testng.xml file, you will get in the output that all tests are passed. In this way, on implementing Page Object Model, we have kept tests and element locators separately that will keep the code clean and easy to understand and maintain.
Let’s move on at a glance at the advantages of Page object model in Selenium WebDriver.
Advantage of Page Object Model in Selenium
There are several advantages of POM in Selenium WebDriver. They are as follows:
1. Clean Separation: Selenium PageObject Model design pattern makes our code cleaner and easy to understand because it helps to separate operations and UI flow from verification.
2. Page Object Repository: Another main advantage of POM is Page Object Repository is independent of automation tests. POM makes object repository independent of test cases so that we can use the same object repository for different purposes with different tools.
For example, the same POM can be used for acceptance testing and functional testing whereas both use a different mechanism for testing.
3. Re-usability: POM makes the code better optimized because of reusable page methods in the POM classes.
4. Easy to maintain.
5. Easy readability of test scripts.
6. Reduce or eliminate duplicate code.
7. Reliability.
Hope that this tutorial has covered almost all the important points related to page object model in Selenium WebDriver with various examples. I hope that you will have understood this tutorial and enjoyed it.
Thanks for reading!!!